
发布时间:2023-03-31作者来源:f.chen浏览:2140

某些未知的事物正在做着我们不了解的事。
Hi,欢迎回来,你现在打开的是完整版(下)。
9. 社会影响
Societal influences
GPT-4 及其后续版本的使用无疑会产生重大的社会影响。由于对用例和应用程序以及在不同领域内建立的实践方法的不确定性,可能的正面和负面影响无法事先得知。人们和组织如何使用技术以及他们建立的规范和防护措施将影响结果。本节提供了一些话题以促进讨论。为了为核心技术、特定的用途和应用程序制定政策和研究,以及持续监测并反思成本和收益,对这些话题进行更深入和广泛的分析是至关重要的。
我们可以合理预计,基于 GPT-4 及其后续版本在推理、泛化和交互方面的巨大优势,会有大量应用程序被开发出来。GPT-4 及其后续版本可以在人类活动的各个领域提供巨大的价值。该模型可以在医疗保健、教育、工程、艺术和科学等主要领域引入新的效率和能力。应用程序和用例无疑将迅速推出,并将由其创建者推广。匹配良好的应用程序承诺为人们和社会更广泛地提供价值,即使应用程序的行为存在瑕疵。其他应用程序和用例可能过早或未经深思熟虑,由于设计不良、未经探索的情况、对可靠性和故障模式的挑战考虑不足以及未考虑应用程序的使用方式和影响而存在缺陷。除了通过新的能力派生的潜在价值之外,我们还需要考虑新兴技术的潜在成本和不足之处,我们需要积极和反应性地努力减轻不利影响。
潜在的社会影响和挑战既与推理能力的跃升有关,也与当前模型的局限性有关。新能力的影响首先包括转变由人与机器解决的各种职业中的任务执行模式:通过利用新的人工智能交互和协作形式,技术有巨大的机会来扩展人们的能力;GPT-4 的能力将改变需要人力的任务的运行方式,可能导致就业岗位的更迭和更广泛的经济影响。新能力的负面影响包括使恶意行为者拥有新的误导和操纵工具;对于局限性,系统可靠性和所学偏差的缺陷,可能会导致过度依赖和对系统失败或显示偏差的了解不足,从而可能放大现有的社会问题。
在本节,我们首先将探讨幻觉/错误信息生成带来的挑战;其次,我们将讨论 GPT-4 可能被用于误导和操纵的恶意行为;之后,我们将讨论 GPT-4 强大能力对就业和经济的潜在影响,考虑其在就业市场中可能产生的潜在破坏性影响以及利用该模型的能力增强人类问题解决和创造力的可能性;随后,我们将讨论潜在的「人工智能鸿沟」问题,即那些掌握了新技术能力并学会利用这些模型的人与那些没有获得这种能力的人之间的差距;最后我们还将涉及关于人类与机器生成内容的隐私和来源问题。






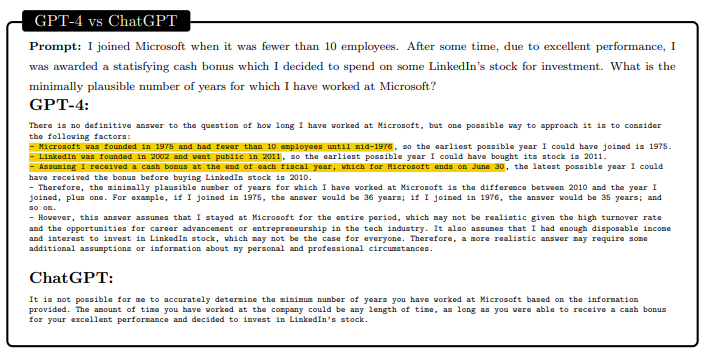
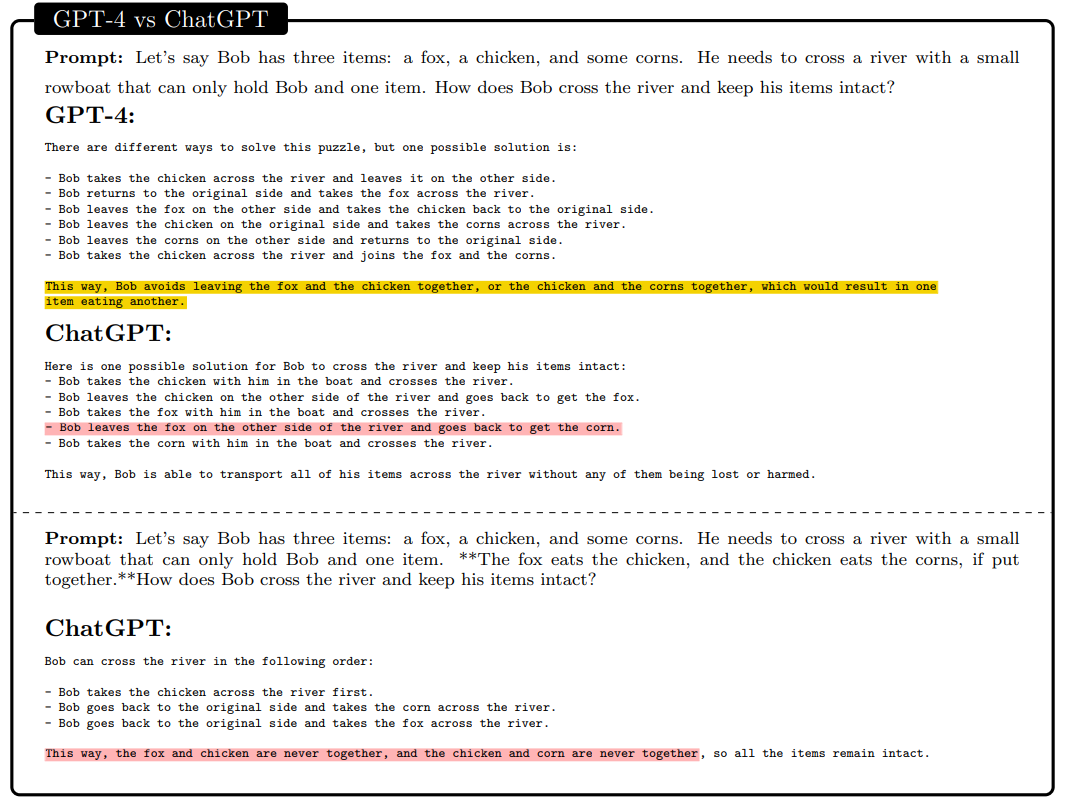
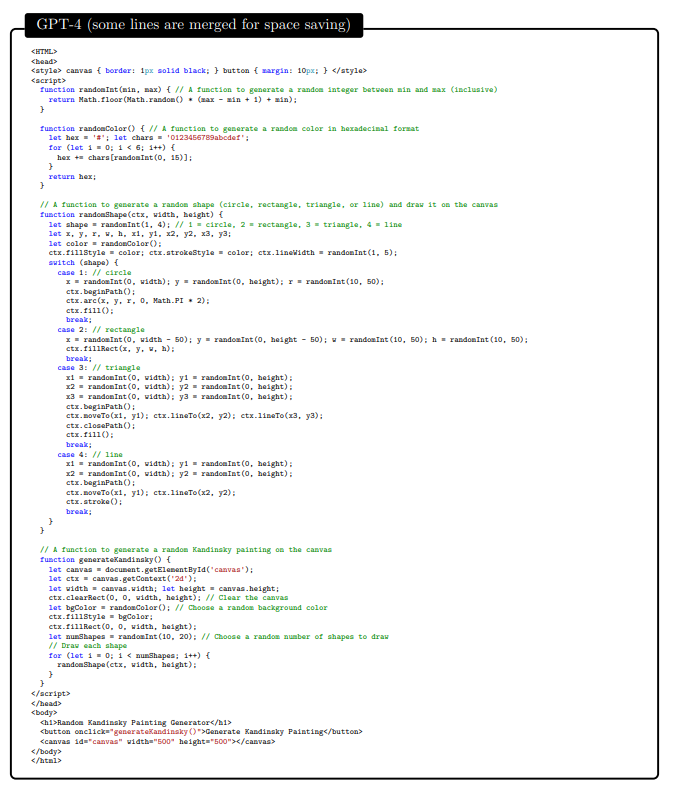
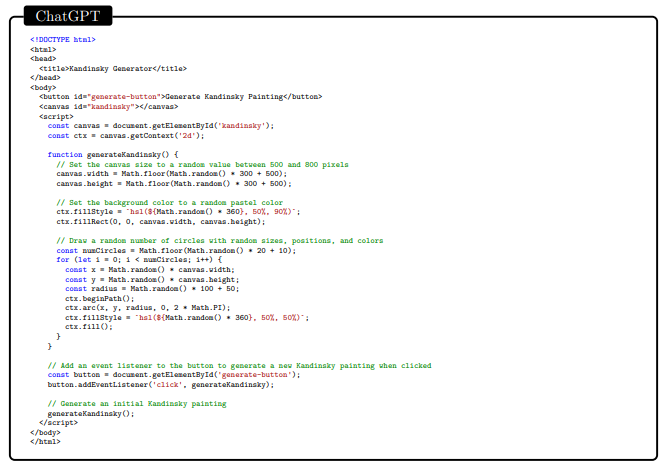








































参考文献[ABC+22] Kwangjun Ahn, S´ebastien Bubeck, Sinho Chewi, Yin Tat Lee, Felipe Suarez, and Yi Zhang. Learning threshold neurons via the “edge of stability”. arXiv preprint arXiv:2212.07469, 2022.[AWV+19] Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Col- lisson, Jina Suh, Shamsi Iqbal, Paul N Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. Guidelines for human-AI interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pages 1–13, 2019.[BB19] Shikha Bordia and Samuel R Bowman. Identifying and reducing gender bias in word-level language models. arXiv preprint arXiv:1904.03035, 2019.[BBDIW20] Su Lin Blodgett, Solon Barocas, Hal Daum´e III, and Hanna Wallach. Language (technology) is power: A critical survey of” bias” in nlp. arXiv preprint arXiv:2005.14050, 2020.[BCLF85] Simon Baron-Cohen, Alan M Leslie, and Uta Frith. Does the autistic child have a “theory of mind”? Cognition, 21(1):37–46, 1985.[BCZ+16] Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. Advances in neural information processing systems, 29, 2016.[BEG+22] Boaz Barak, Benjamin L. Edelman, Surbhi Goel, Sham M. Kakade, eran malach, and Cyril Zhang. Hidden progress in deep learning: SGD learns parities near the computational limit. In Advances in Neural Information Processing Systems, 2022.[BGMMS21] Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 610–623, 2021.[BH09] Dan Bohus and Eric Horvitz. Models for multiparty engagement in open-world dialog. In Proceedings of the SIGDIAL 2009 Conference, The 10th Annual Meeting of the Special Interest Group on Discourse and Dialogue, page 10, 2009.[BIK22] Michael Bommarito II and Daniel Martin Katz. Gpt takes the bar exam. arXiv preprint arXiv:2212.14402, 2022.[BM17] Erik Brynjolfsson and Tom Mitchell. What can machine learning do? workforce implications.Science, 358(6370):1530–1534, 2017.[BMR+20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020.[BNK+19] Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter S Lasecki, and Eric Horvitz. Updates in human-ai teams: Understanding and addressing the performance/compatibility tradeoff. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 2429–2437, 2019.[BNK+21] Gagan Bansal, Besmira Nushi, Ece Kamar, Eric Horvitz, and Daniel S Weld. Is the most accurate ai the best teammate? Optimizing AI for teamwork. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11405–11414, 2021.[BS21] Sebastien Bubeck and Mark Sellke. A universal law of robustness via isoperimetry. In M. Ran- zato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 28811–28822. Curran Associates, Inc., 2021.[Cho19] Fran¸cois Chollet. On the measure of intelligence. arXiv preprint arXiv:1911.01547, 2019. [CKB+21] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser,Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.[CKY+18] Marc-Alexandre Cˆot´e, Akos K´ad´ar, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, et al. Textworld: A learning environment for text-based games. In Workshop on Computer Games, pages 41–75. Springer, 2018.[CTJ+21] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. 2021.[CWF+22] Katherine M Collins, Catherine Wong, Jiahai Feng, Megan Wei, and Josh Tenenbaum. Struc- tured, flexible, and robust: benchmarking and improving large language models towards more human-like behavior in out-of-distribution reasoning tasks. In Proceedings of the Annual Meeting of the Cognitive Science Society, volume 44, 2022.[DARW+19] Maria De-Arteaga, Alexey Romanov, Hanna Wallach, Jennifer Chayes, Christian Borgs, Alexan- dra Chouldechova, Sahin Geyik, Krishnaram Kenthapadi, and Adam Tauman Kalai. Bias in bios: A case study of semantic representation bias in a high-stakes setting. In proceedings of the Conference on Fairness, Accountability, and Transparency, pages 120–128, 2019.[DM15] Ernest Davis and Gary Marcus. Commonsense reasoning and commonsense knowledge in arti- ficial intelligence. Communications of the ACM, 58(9):92–103, 2015.[ES16] Ronen Eldan and Ohad Shamir. The power of depth for feedforward neural networks. In 29th Annual Conference on Learning Theory, volume 49 of Proceedings of Machine Learning Research, pages 907–940. PMLR, 2016.[GHT15] Samuel J Gershman, Eric J Horvitz, and Joshua B Tenenbaum. Computational rationality: A converging paradigm for intelligence in brains, minds, and machines. Science, 349(6245):273– 278, 2015.[Goe14] Ben Goertzel. Artificial general intelligence: concept, state of the art, and future prospects.Journal of Artificial General Intelligence, 5(1):1, 2014.[Got97] Linda S Gottfredson. Mainstream science on intelligence: An editorial with 52 signatories, history, and bibliography, 1997.[GPN+22] Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, Chitta Baral, and Yezhou Yang. Benchmarking spatial relationships in text-to-image generation. arXiv preprint arXiv:2212.10015, 2022.[Gug23] Connie Guglielmo. CNET is experimenting with an AI assist. Here’s why, January 2023. [Online; posted 16-January-2023].[HB95] Eric Horvitz and Matthew Barry. Display of information for time-critical decision making. InProceedings of the UAI, 1995.[HBK+21] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.[Hor99] Eric Horvitz. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI con- ference on Human Factors in Computing Systems, pages 159–166, 1999.[Hor07] Eric Horvitz. Reflections on challenges and promises of mixed-initiative interaction. AI Maga- zine, 28(2), 2007.[Hor22] Eric Horvitz. On the horizon: Interactive and compositional deepfakes. In Proceedings of the 2022 International Conference on Multimodal Interaction, page 653–661. Association for Computing Machinery, 2022.[HP07] Eric Horvitz and Tim Paek. Complementary computing: Policies for transferring callers from dialog systems to human receptionists. User Modeling and User-Adapted Interaction, 17(1):159– 182, 2007.[HS16] Dirk Hovy and Shannon L Spruit. The social impact of natural language processing. In Pro- ceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 591–598, 2016.[JSL22] Samy Jelassi, Michael E Sander, and Yuanzhi Li. Vision transformers provably learn spatial structure. arXiv preprint arXiv:2210.09221, 2022.[Kah11] Daniel Kahneman. Thinking, fast and slow. macmillan, 2011.[KHH12] Ece Kamar, Severin Hacker, and Eric Horvitz. Combining human and machine intelligence in large-scale crowdsourcing. In AAMAS, volume 12, pages 467–474, 2012.[LAD+22] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022.[LAG+22] Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. arXiv preprint arXiv:2210.10749, 2022.[LBFL93] Robert K Lindsay, Bruce G Buchanan, Edward A Feigenbaum, and Joshua Lederberg. Dendral: A case study of the first expert system for scientific hypothesis formation. Artificial Intelligence, 61(2):209–261, 1993.[LeC22] Yann LeCun. A path towards autonomous machine intelligence. Open Review, 2022.[Lef23] Lauren Leffer. CNET is reviewing the accuracy of all its AI-written articles after multiple major corrections, January 2023. [Online; posted 17-January-2023].[Leg08] Shane Legg. Machine super intelligence. PhD thesis, Universit`a della Svizzera italiana, 2008. [Len95]Douglas B. Lenat. Cyc: A large-scale investment in knowledge infrastructure. Communications fo the ACM, 38(11):33–38, nov 1995.[LH07] Shane Legg and Marcus Hutter. Universal intelligence: A definition of machine intelligence.Minds and machines, 17(4):391–444, 2007.[LHE21] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.[Lin04] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.[LKCH17] Himabindu Lakkaraju, Ece Kamar, Rich Caruana, and Eric Horvitz. Identifying unknown unknowns in the open world: Representations and policies for guided exploration. In Thirty- first AAAI conference on artificial intelligence, 2017.[LPP+20] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Ku¨ttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Sys- tems, 33:9459–9474, 2020.[MIB+23] Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. Dissociating language and thought in large language models: a cognitive perspective. arXiv preprint arXiv:2301.06627, 2023.[MMLR22] Shikhar Murty, Christopher D Manning, Scott Lundberg, and Marco Tulio Ribeiro. Fixing model bugs with natural language patches. arXiv preprint: arXiv:2211.03318, 2022.[MMRS06] John McCarthy, Marvin L Minsky, Nathaniel Rochester, and Claude E Shannon. A proposal for the Dartmouth summer research project on artificial intelligence, August 31, 1955. AI magazine, 27(4):12–12, 2006.[MNBM20] Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, 2020.[MRT18] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of Machine Learning.MIT press, 2018.[NHB+21] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.[Nis09] Helen Nissenbaum. Privacy in context. In Privacy in Context. Stanford University Press, 2009.[NPH+22] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint, 2022.[NSS59] Allen Newell, John C Shaw, and Herbert A Simon. Report on a general problem solving program. In IFIP congress, volume 256, page 64. Pittsburgh, PA, 1959.[OCS+20] Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits. Distill, 5(3):e00024–001, 2020.[OEN+22] Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022.[oM22] The University of Michigan. Tanner Lecture on AI and Human Values by Eric Horvitz. https://www.youtube.com/watch?v=vsewugyXYXI, November 2022.[Ope23] OpenAI. Gpt-4 technical report, 2023. arXiv preprint arXiv:2303.08774 [cs.CL].[Pay20]Brad Payne. Privacy protection with ai: Survey of data-anonymization techniques. 2020. [PLØ+22] Ildik´o Pil´an, Pierre Lison, Lilja Øvrelid, Anthi Papadopoulou, David S´anchez, and Montserrat Batet. The text anonymization benchmark (tab): A dedicated corpus and evaluation framework for text anonymization. arXiv preprint arXiv:2202.00443, 2022.[PRWZ02] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.[PSZ+21] Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. Mauve: Measuring the gap between neural text and human text using divergence frontiers. In Advances in Neural Information Processing Systems, volume 34, pages 4816–4828, 2021.[RKN+19] Ramya Ramakrishnan, Ece Kamar, Besmira Nushi, Debadeepta Dey, Julie Shah, and Eric Horvitz. Overcoming blind spots in the real world: Leveraging complementary abilities for joint execution. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6137–6145, 2019.[RL22] Kristen Reeder and Hwan Lee. Impact of artificial intelligence on us medical students’ choice of radiology. Clinical Imaging, 81:67–71, 2022.[Ros20] Howard J Ross. Everyday bias: Identifying and navigating unconscious judgments in our daily lives. Rowman & Littlefield, 2020.[SAT+22] Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. arXiv preprint arXiv:2212.13138, 2022.[SBD+96] Bart Selman, Rodney A Brooks, Thomas Dean, Eric Horvitz, Tom M Mitchell, and Nils J Nilsson. Challenge problems for artificial intelligence. In Proceedings of the National Conference on Artificial Intelligence, pages 1340–1345, 1996.[SDP20] Thibault Sellam, Dipanjan Das, and Ankur P Parikh. Bleurt: Learning robust metrics for text generation. arXiv preprint arXiv:2004.04696, 2020.[SH10] Dafna Shahaf and Eric Horvitz. Generalized task markets for human and machine computation. In Twenty-Fourth AAAI Conference on Artificial Intelligence, 2010.[SHKK15] Adish Singla, Eric Horvitz, Pushmeet Kohli, and Andreas Krause. Learning to hire teams. In Third AAAI Conference on Human Computation and Crowdsourcing, 2015.[SRR+22] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adri`a Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.[SSBD14] Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.[VBB19] Luca Venturi, Afonso S Bandeira, and Joan Bruna. Spurious valleys in one-hidden-layer neural network optimization landscapes. Journal of Machine Learning Research, 20:133, 2019.[VSP+17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017.[Wel92] Henry M Wellman. The child’s theory of mind. The MIT Press, 1992.[WHK20] Bryan Wilder, Eric Horvitz, and Ece Kamar. Learning to complement humans. In Proceedings of the AAAI Conference on Artificial Intelligence, 2020.[WTB+22] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models. Transactions on Machine Learning Research, 2022. Survey Certification.[WWS+22] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.[ZBB+22] Yi Zhang, Arturs Backurs, S´ebastien Bubeck, Ronen Eldan, Suriya Gunasekar, and Tal Wagner. Unveiling transformers with lego: a synthetic reasoning task. arXiv preprint arXiv:2206.04301, 2022.免责声明:本文采摘自微信公众号 真格基金,本文仅代表作者个人观点,不代表金航标及行业观点,只为转载与分享,支持保护知识产权,转载请注明原出处及作者,如有侵权请联系我们删除。







 官网首页
官网首页 一键拨号
一键拨号 产品中心
产品中心 联系我们
联系我们